The situation
A large enterprise software company runs a platform that lets its customers capture, search, and produce archived business communications — the kind of system that has to stand up to compliance audits and legal discovery, where missing a responsive record is not an option. Search is a critical feature of that product. Customers come to it specifically to find the right records inside enormous, sensitive archives, often under legal deadline.
That search platform was built on Apache Solr. But over years of feature work it had drifted in a direction that became problematic: at point after point, the team had written custom code in place of capabilities Solr already ships and has hardened across thousands of production deployments. Custom routing instead of the engine’s standard clustering and sharding. A custom join implementation instead of the engine’s native one. A stack of custom plugins, several of which reached into the product’s own codebase — coupling the search engine so tightly to the application that a change in one could force a restart of the other.
Each of those decisions had been reasonable in isolation. In aggregate they had turned into a tax. The platform was carrying more documents per tenant on smaller, more numerous shards than it needed to; ingestion ran one document at a time, which is the slowest way to feed Solr and the most painful when a large archive has to be rebuilt or recovered. The largest customers were packed onto the same footprint as the smallest, so the heaviest tenants set the pace for everyone. Query performance was reported as slow even though the workload was read-light. And because so much logic lived in custom code, every scaling decision came with a maintenance bill and a coupling risk attached.
The question the team faced is a familiar one for any mature search platform: how much of this custom code is actually carrying its weight, and how much of it is standing between us and the scale, cost, and reliability we need?
Why they called us
They came to us already knowing the depth of expertise they’d be working with — the team had trained with Grant Ingersoll before they ever became a client.
When they needed an outside read on the platform, the deciding factor was straightforward: the depth of Solr experience across the Develomentor team. A review like this only pays off if the reviewer can read the actual schema, weigh each custom plugin against what the engine already does natively, and judge — with authority — what to keep, what to push back upstream into open source, and what to retire entirely. That calls for engine-level expertise, not a generalist’s checklist.
The engagement was led by Grant Ingersoll — a core Apache Lucene and Solr committer and author of Taming Text — delivering alongside a team of senior Develomentor search practitioners. That combination is exactly what an over-customized open-source search platform demands: the hands-on engine depth to diagnose what the custom code is really costing, and the seniority to make the keep-or-replace calls with evidence behind them.
What we did
The health check
We ran a Search Health Check: a fast, evidence-based review of the platform across architecture, indexing, querying, custom code, and production operations. Working with the client’s engineering, product, and leadership teams, we audited the schema, configuration, JVM settings, and the custom code in the search path, and benchmarked where time and money were actually going rather than guessing.
The platform handles sensitive customer data, so parts of the runtime were deliberately opaque — query-level logging was disabled for privacy and security reasons. We flagged that as its own finding: without visibility into the structure of real queries, performance, debugging, and auditability all suffer. Where the runtime was dark, we worked from the codebase, the configuration, and what telemetry was available, and named the observability gap as something to close.
The output was a prioritized set of recommendations — a clear “do now” shortlist at the front, with the supporting evidence behind it — rather than a vague list of best practices.
A guiding principle: customize the engine as little as possible
The through-line of the diagnosis was simple to state and hard-won to apply: open source lets you modify the engine, but every modification you own is a modification you have to maintain, secure, and carry forward. Customization should be a last resort, not a first instinct. Most of what the platform had hand-rolled, Solr already did — often better, and always with the open-source community sharing the maintenance burden.
So the work was largely about separating the custom code that genuinely earned its keep from the code that should be handed back to the engine:
- Standardize on the engine’s built-in clustering and routing in place of the custom routing layer, so scaling follows a proven, well-documented path instead of a bespoke one.
- Replace the custom join with Solr’s native join, removing a fragile, expensive component — and, with the right indexing changes, potentially removing whole classes of joins altogether.
- Decouple the search engine from the application’s query code. Several plugins had tied Solr directly to the product’s own codebase; moving that logic out of the engine removes the coupling that made fixes risky and restarts contagious.
- Push genuinely useful extensions upstream. Where a customization was actually valuable, the right home for it was a patch to the open-source project — so the community maintains it, not the client’s team in a private fork.
Indexing built for scale, not one document at a time
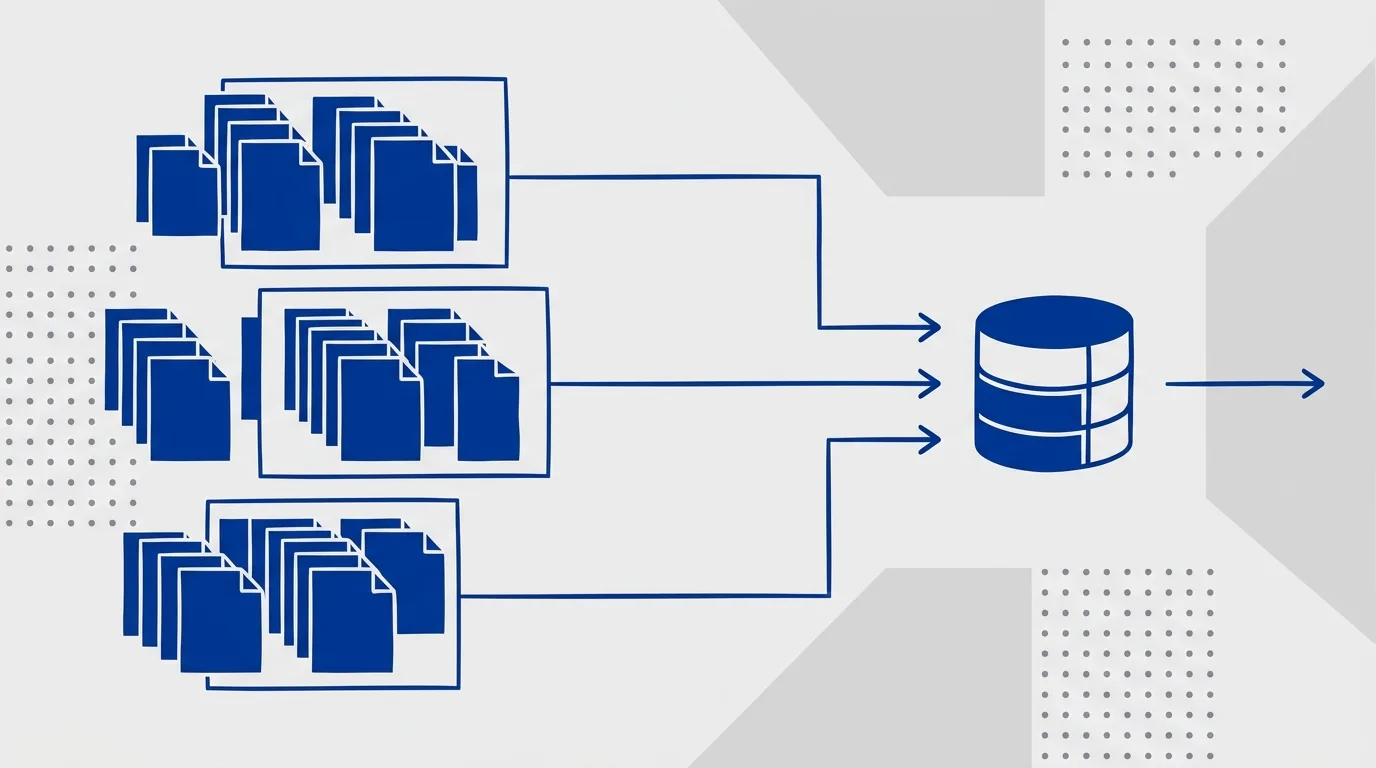
The single highest-leverage change was on the ingestion path. Feeding the engine one document at a time underperforms in real time, bloats storage, and turns bulk loads, rebuilds, and recovery into ordeals. We laid out a move to batched, bulk-oriented indexing — sending documents in windows, packing source files into efficient columnar and compressed formats instead of many tiny objects, and using parallel, distributed compute for large (re)loads. For a platform that periodically has to rebuild large, sensitive archives, that’s the difference between a recovery being a routine operation and being an all-hands event.
Right-sizing the footprint and the tenancy model

We also recommended consolidating onto fewer, larger, appropriately-shaped nodes — more documents per shard, JVM heap tuned into the range where garbage collection behaves, and a replica strategy chosen for both cost and resilience. And we laid out a tenancy strategy by customer size and priority: isolate and properly resource the largest customers (including their ingestion) so a few heavy tenants no longer set the performance ceiling for everyone, while packing smaller customers densely and promoting them as they grow. Turning on caching, with a deliberate refresh strategy, was part of the same cost-and-performance picture.
Staying on to implement
A roadmap that sits on a shelf changes nothing. After the Health Check, a senior Develomentor search engineer stayed on for roughly two months in a staff-augmentation role, working alongside the client’s engineers to begin executing the recommendations and to assist with broader search engineering and operations — turning the diagnosis into delivered change rather than a slide deck.
The result
The headline outcome was clarity backed by evidence: a platform team that had been weighing scaling decisions against an opaque tangle of custom code came away with a prioritized, defensible plan for what to keep, what to retire, and what to hand back to the open-source engine — and with senior hands on the ground to start carrying it out.
Concretely, the engagement left the client with:
- Implementation underway, not just advised. A senior engineer embedded with the team and began executing the highest-priority changes, so the roadmap turned into progress rather than a slide deck.
- A path off fragile custom code. A clear, prioritized plan to replace custom routing and a custom join with the engine’s proven built-in capabilities, and to decouple the search engine from the application — reducing the maintenance and coupling risk that had made every change costly.
- An indexing model built for scale and recovery. A move from one-document-at-a-time ingestion to batched, bulk-oriented indexing designed to make real-time updates, bulk loads, and archive rebuilds dramatically less painful.
- A tenancy and footprint strategy. A plan to isolate the largest customers and consolidate onto a right-sized footprint, so the platform scales on cost and performance instead of node count.
Because the work was about retiring custom code in favor of capabilities the engine already maintains, the durable win is lower long-term cost — less code to own, secure, and carry forward — on a foundation the open-source community keeps improving.
What this means for you
If you’ve spent years quietly replacing your search engine with your own code — custom routing, custom joins, custom plugins reaching into your application — there’s a good chance that code is now the thing standing between you and the scale, cost, and reliability you need. The instinct that got you here (“we can just build it ourselves”) is the same instinct worth questioning now.
The fix usually isn’t more custom code. It’s a clear-eyed, engine-level diagnosis that separates the customizations earning their keep from the ones quietly taxing you — and a concrete plan to hand the rest back to capabilities the engine already ships and hardens for you. Done right, you end up with less code to maintain, a cheaper and more scalable footprint, and a platform your team can actually reason about.
That diagnosis is exactly what a Search Health Check delivers — the fastest way to get an expert read on where your search is over-built and what to do about it. And our Search & AI Builders practice is where the implementation lives.
Tell us where your search platform stands today. Book a Discovery Call.